

La réplication est un mécanisme important pour garantir une haute disponibilité. Que vous disposiez d’une licence Enterprise ou Standard, plusieurs solutions s’offrent à vous. Le choix final sera décidé en prenant en compte plusieurs critères, tels que vos objectifs de continuité de service, vos contraintes matérielles, la charge de travail, ou encore la tolérance à la perte de données.
Voici les principales solutions à disposition, accompagné des avantages et inconvénients associés.
Mise en miroir de bases de données (Mirroring)
La mise en miroir s’implémente au niveau base de données et est considérée comme l’ancêtre des groupes de disponibilité AlwaysOn, que nous présentons un peu plus loin dans l’article.
Cette fonctionnalité a été dépréciée et a finit par être supprimé par Microsoft.
Principe de fonctionnement
Le serveur principal (source) et le serveur miroir (cible) communiquent en tant que serveurs partenaires dans une session de mise en miroir de bases de données. Contrairement à la réplication AlwaysOn qui est une réplication dite logique, la réplication sur le principe du mirroring envoie et applique les enregistrements trouvés dans le journal de transaction log (physique).
Avantage
- Validation asynchrone (mode hautes performances) ou synchrone (mode haute sécurité)
- Basculement de rôle automatique ou manuelle (avec ou sans perte de données)
Inconvénient
Nous ne pouvons ignorer que la fonctionnalité sera supprimé sur les nouvelles versions SQL Server, il est donc inconcevable de développer une application autour d’un produit obsolète.
Instances de cluster de basculement (FCI)
Un autre ancêtre des groupes de disponibilité AlwaysOn reste l’incontournable FCI, autrement dit Failover Cluster Instance. Celles-ci reposent sur le clustering de basculement Windows Server (WSFC).
Principe de fonctionnement
C’est une configuration où plusieurs nœuds partagent une même instance, installée sur un stockage partagé. Votre instance existe sur un nœud à la fois, et en cas de défaillance de l’un deux, le WSFC bascule les ressources partagées en les balançant d’un nœud à l’autre.
Avantage
- Haute disponibilité avec basculement automatique
- Prise en charge de disques iSCSI, Fibre Channel, partages de fichiers SMB etc..
- Basculement (quasi) transparent pour les connexions clientes
- Maintenance planifiée des serveurs possible
Inconvénient
- Point de défaillance unique : Les disques
- Les données et/ou les disques partagées peuvent être soumises à des corruptions ou autre fait indésirable
- Et à cela, Microsoft a répondu par les groupes de disponibilités AlwaysOn
Vous l’aurez compris, la FCI offre une haute disponibilité, mais on note une faiblesse pour la récupération d’urgence.
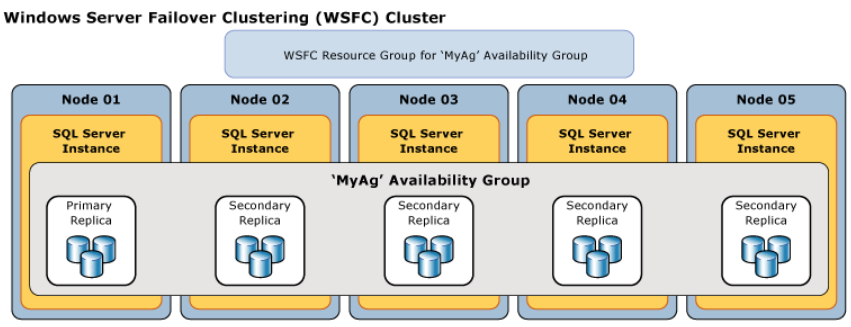
Groupe de disponibilités AlwaysOn
Un groupe de disponibilité est un regroupement logique d’une ou plusieurs bases de données répliquées, et offre pour la première fois (contrairement au solution précédente) la possibilité d’un réplica en lecture seule ; idéal pour décharger la base de données primaire des opérations de lecture.
Principe de fonctionnement
Le déploiement des groupes de disponibilités AlwaysOn nécessite un cluster de basculement Windows Server (WSFC) qui surveille en permanence les ressources afin d’évaluer l’intégrité du réplica principal. Chaque transaction est logiquement envoyée sur chaque réplica secondaire via des points de terminaison sur le port 5022 (par défaut).
Avantage
- Chaque instance possède une copie de données hébergées en local
- Réparation de page automatique (récupération de la page sur la copie de données de l’autre nœud)
- Mode de validation asynchrone ou synchrone
- Basculement automatique ou manuelle (avec ou sans perte de données)
- Possibilité d’avoir jusqu’à 8 réplicas secondaires
- Fonctionnalité disponible même en Standard Edition (AlwaysOn Basic), avec toutefois quelques limitations notables
- Prise en charge d’un écouteur (listener) pour chaque groupe de disponibilités, offrant un point d’entrée unique pour les connexions applicatives
- Possibilité de créer un routage automatique pour les charges de travail en lecture seule
- Compatible avec d’autres fonctionnalités comme le Change Data Capture (CDC), le suivi de modifications ou le FILESTREAM
- Synchronisation initiale via Seed Auto facilitant l’intégration de nouvelles bases dans un AG
- Idéal pour la maintenance et les montées de version des serveurs/instances en mode Rolling Update
Inconvénient
Il n’y en a pas. C’est, de loin, la meilleure alternative (peut être le prix des licences…)
Log Shipping
Le Log Shipping est une autre alternative permettant d’avoir un réplica secondaire pour une récupération d’urgence.
Principe de fonctionnement
Ce mode de réplication se base cette fois-ci sur les sauvegardes du journal de transactions d’une base primaire qui sont restaurés sur une base secondaire (disponible en read only mais reste limité). A la création de la configuration Log Shipping, trois jobs sont créés au niveau de l’Agent SQL :
- Un job de sauvegarde de journal de transactions (BACKUP LOG) (présent sur l’instance primaire uniquement)
- Un job de copie qui va copier les sauvegardes effectuées du serveur primaire vers le ou les serveurs secondaires (présent sur l’instance secondaire uniquement)
- Un job de restauration de la sauvegarde du journal (présent sur l’instance secondaire uniquement)
Les travaux de copie et de restauration sont dupliquées pour autant de bases que vous souhaitez répliquer.
Avantage
- Disponible en Standard Edition et reste une approche peu onéreuse d’avoir un PRA pour une base de données
- Possibilité d’implémenter une troisième instance (optionnelle) dite Moniteur de serveur pour surveiller l’état de la réplication/synchronisation et ainsi pouvoir envoyer des notifications d’alertes.
Inconvénient
- Pas de possibilité de basculement automatique
- D’autant qu’il s’agit d’un mode de réplication qui s’implémente au niveau de chaque base de données, le processus de récupération d’urgence est manuelle et répétitif (à faire autant de fois qu’il y a de bases répliquées sur l’instance). Ce qui a une incidence directe sur le RTO (Recovery Time Objective).
- D’autant aussi que ce mode de réplication est unidirectionnel, le retour à l’état nominal implique dans bien des cas à une restauration de base.
- Le RPO (Recovery Point Objective) est lié à la fréquence à laquelle les jobs backup/copie/restore se lancent. S’ils s’exécutent toutes les 10 mins, vous risquez donc de perdre des données dans le cadre de la récupération d’urgence. A l’inverse, si vous les exécutez à intervalle trop proche (pour diminuer le RPO), il est à prendre en considération que la base de données dite standby est passée en SINGLE_USER lors de chaque opération de restauration, et ne peux donc servir de base secondaire pour décharger les charges de travail de lecture seule, ou alors de manière très limité (déconnexion intempestive des connexions).
Réplication transactionnelle
La réplication transactionnelle est le mode de réplication qui offre la granularité la plus faible, avec la possibilité de choisir le ou les objets à répliquer (table, schéma, procédure, vue).
Principe de fonctionnement
Une fois l’instantané initial effectué, les changements de données soumis au serveur de Publication (source) sont transmis à l’Abonné (cible) par l’intermédiaire d’un serveur de distribution (qui peut être le même que le serveur de Publication). L’Agent de lecture du journal surveille le journal des transactions de chaque base de données configurée pour la réplication transactionnelle et copie les transactions devant être répliquées à partir du journal des transactions dans la base de données de distribution, laquelle joue le rôle de file d’attente de stockage et transfert. L’Agent de distribution copie les fichiers d’instantanés initiaux du dossier d’instantanés et les transactions conservées dans les tables de la base de données de distribution vers les Abonnés.
Avantage
- Latence minimale (lorsque l’Agent de distribution tourne en continu)
- Scalabilité horizontale possible sur les charges de travail de lecture en tirant parti de la réplication dite égal à égal (Peer-to-Peer)
- C’est la seule solution offrant une configuration active/active en tirant parti de la réplication transactionnelle bidirectionnelle & de la réplication dit à abonnements pouvant être mis à jour avec gestion des conflits. Ainsi, il est possible d’avoir un abonné pouvant être mis à jour, au même titre que le serveur de publication. Les modifications sont ainsi propagées dans le sens inverse.
- Toutes les éditions de SQL Server peuvent servir d’abonnées. Il est donc possible d’instancier une édition Express (gratuite) pour servir de standby (sous réserve que la volumétrie totale répliquée ne dépasse 10 GB de données)
Inconvénient
- Complexification dans le troubleshooting d’incidents de réplication
- Une clé primaire est nécessaire sur toutes les tables impliquées dans la réplication (sert de localisateur d’enregistrement pour toutes les requêtes). De ce que fait, les tables de Heap sans contrainte d’unicité ne peuvent pas être répliquées.
- Les index non cluster ne sont pas répliquées (option à False par défaut)
- Mode de réplication très susceptible à la latence et au débit serveur, qui peuvent grandement influé sur les performances
- Déconseillé lorsque nous devons répliquer une base de données entière ou une trop grande quantité d’objets
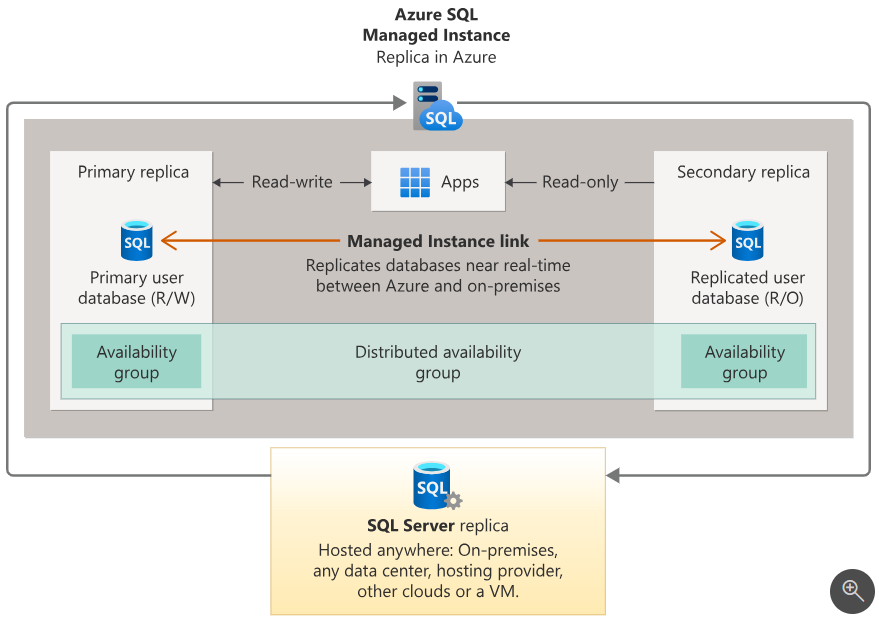
Lien Azure Managed Instance
La liaison Managed Instance offre une solution de réplication hybride, compatible depuis SQL Server 2016, entre une instance SQL Server et une Azure SQL Managed Instance(MI). Elle permets notamment l’utilisation des services Azure sans migrer complétement dans le Cloud (comme Azure Synapse Analytics, Logics apps, Azure Dara Factory, etc).
Principe de fonctionnement
La liaison repose sur les groupes de disponibilités distribués.
Avantage
- Idéal pour décharger des charges de travail de lecture sur le Cloud Azure et tirer parti de toutes les possibilités d’Azure (scalabilité à la demande, maintenance assurée par le provider, flexibilité sur les licences, sauvegardes automatisées)
- Possibilité de payer la licence dans le forfait pay-as-you-go sans en acquérir une ; ou de bénéficier d’une réduction du tarif (autrement appelé réplica de récupération d’urgence passive sans licence) grâce au Azure Hybrid Benefit si vous possédez une licence de votre serveur on-premises avec la Software Assurance
- La migration vers le Cloud est ainsi facilitée, offrant un temps d’arrêt minimal dans le cadre d’une migration.
Inconvénient
- La réplication bidirectionnelle n’est disponible qu’à partir de SQL Server 2022.
- Si vous utilisez SQL Server 2016, 2017 ou 2019 en tant que version du serveur source, la bascule est unidirectionnelle. De ce fait, il se sera plus possible de simplement retourner à l’état nominal.
En résumé
Une architecture en standalone sur la production est un risque car le moindre incident entraîne un temps d’arrêt difficilement acceptable pour la plupart des applications critiques.
Dans ce contexte, la mise en place d’un mécanisme de réplication ou de haute disponibilité n’est plus une option, mais une nécessité pour assurer la continuité de service, et comme vous avez pu le voir, il y a forcément une solution adaptée à vos besoins.
N’hésitez pas à nous contacter si vous souhaitez aller plus loin sur ces sujets. Axians Data Management se rendra disponible pour vous accompagner sur cette thématique de réplication ou pour tout autre sujet d’infrastructure de base de données.