

Vous avez une base Oracle et vous souhaitez capturer en temps réel tous les INSERT, UPDATE et DELETE pour les envoyer instantanément dans Kafka ? Debezium est une solution open source très répandu pour le réaliser.
Qu’est-ce que Debezium ?
Debezium est un outil Change Data Capture (CDC) open source qui transforme votre base de données en flux d’événements. Il lit les journaux de transaction (redo logs) sans impact notable sur les performances de la base, et publie chaque modification sous forme de message Kafka.
Avantages majeurs :
- Très faible latence (quelques centaines de ms)
- Zéro perte de données (même en cas de redémarrage)
- Snapshot initial automatique
- Support complet des schémas (évolution de table gérée)
De cette manière vos données Oracle seront disponibles et utilisables au sein d’autres applications rapidement et simplement.
Il supporte de nombreux moteurs de bases de données, Oracle n’est qu’une source possible parmi d’autres
Côté Oracle, l’extraction se fait principalement via LogMiner (par défaut). Il n’y a pas de surcoût, c’est inclus dans toutes les éditions d’Oracle. L’utilisation de XStream est aussi supportée.
Configuration de la base Oracle
-- Activer l'archivelog (obligatoire)
ALTER DATABASE ARCHIVELOG;
-- Supplemental logging global
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (PRIMARY KEY) COLUMNS;
-- Création de l'utilisateur Debezium
CREATE USER dbzuser IDENTIFIED BY MonSuperMotDePasse2026
DEFAULT TABLESPACE USERS QUOTA UNLIMITED ON USERS;
GRANT CREATE SESSION, CREATE TABLE, CREATE SEQUENCE TO dbzuser;
GRANT EXECUTE ON DBMS_LOGMNR TO dbzuser;
GRANT SELECT ON V_$LOG, V_$LOG_HISTORY, V_$LOGMNR_LOGS, V_$LOGMNR_CONTENTS,
V_$DATABASE, V_$THREAD, V_$PARAMETER TO dbzuser;
GRANT SELECT_CATALOG_ROLE, EXECUTE_CATALOG_ROLE TO dbzuser;
GRANT SELECT ANY TRANSACTION, LOGMINING TO dbzuser;
GRANT FLASHBACK ANY TABLE TO dbzuser; -- recommandé
-- Pour chaque table à capturer
ALTER TABLE MON_SCHEMA.MA_TABLE ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
-- pour chaque objet, il faut ajouter les droits en lecture
GRANT SELECT ON MON_SCHEMA.MA_TABLE TO dbzusers;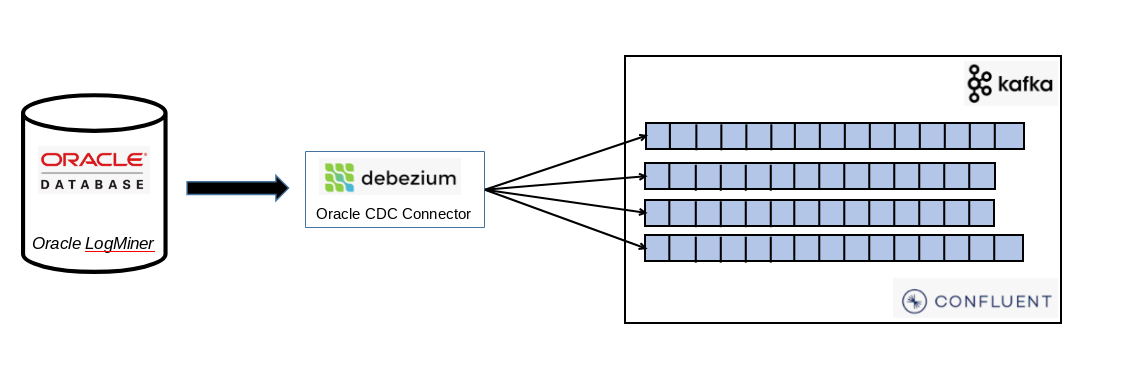
Configuration de Debezium pour Oracle
La méthode la plus simple pour faire tourner Debezium est de le faire en mode containerisé soit via docker soit dans l’idéal sur Kubernetes ou mieux avec l’opérateur Strimzi qui embarque aussi la gestion d’un cluster Kafka.
La configuration Debezium se fait via l’api REST directement.
Votre container/pod doit être démarré et accessible, pour vérifier son état :
curl -H "Accept:application/json" localhost:8083
{"version":"4.1.1","commit":"be816b82d25370ce","kafka_cluster_id":"12345"}Pour vérifier les connecteurs déjà configurés :
curl -H "Accept:application/json" localhost:8083/connectors/Si vous n’avez aucun connecteurs actuellement configurés, il vous renverra un array json vide : []
Un exemple de configuration sur l’url /connectors en POST (supprimez les commentaires si vous voulez copier/coller, ils sont mis à titre informatif)
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" \
http://localhost:8083/connectors/ \
-d '{
"name": "oracle-cdc", //nom du connecteur
"config": {
"connector.class": "io.debezium.connector.oracle.OracleConnector",
"tasks.max": "1",
"database.hostname": "monserveuroracle", // l'adresse de votre serveur
"database.port": "1521",
"database.user": "debezium", //utilisateur pour se connecter à la base Oracle
"database.password": "debezium", // mot de passe associé
"database.dbname": "TEST19", //SID
"database.server.name": "oracle-prod", // nom du topic sur KAFKA dans lequel les données remonteront
"table.include.list": "NMU.TEST_TABLE", // nom des tables à inclure
"schema.include.list": "NMU", // nom des schémas à inclure
"snapshot.mode": "initial", // chargement initial des données si vous le souhaitez
"log.mining.strategy": "online_catalog",
"log.mining.continuous.mine": "true",
"topic.prefix": "cdc", // prefix pour le topic kafka
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": "false",
"value.converter.schemas.enable": "false",
"include.schema.changes": "true",
"schema.history.internal.kafka.bootstrap.servers": "kafka:9092", //l'adresse du/des serveurs kafka pour envoyer les données
"schema.history.internal.kafka.topic": "schemahistory.oracle-prod"
}
}'Vérification du statut du connecteur Debezium
Une fois envoyé, vous pouvez vérifier le statut avec la commande suivante (le | jq permet un affichage propre du json retourné) :
curl -H "Accept:application/json" localhost:8083/connectors/monconnecteur/status | jq
{
"name": "monconnecteur",
"connector": {
"state": "RUNNING",
"worker_id": "172.17.0.4:8083",
"version": "3.4.1.Final"
},
"tasks": [
{
"id": 0,
"state": "RUNNING",
"worker_id": "172.17.0.4:8083",
"version": "3.4.1.Final"
}
],
"type": "source"
}En consultant les logs Debezium après avoir inserer une ligne dans la table Oracle :
2026-02-17T09:40:03,629 INFO || 2 records sent during previous 17:27:21.749, last recorded offset of {server=cdc} partition is {commit_scn=27638340:1:0900020048500000, txSeq=1, txId=01000300793d0000, snapshot_scn=27332570, scn=27638326} [io.debezium.connector.common.BaseSourceTask]
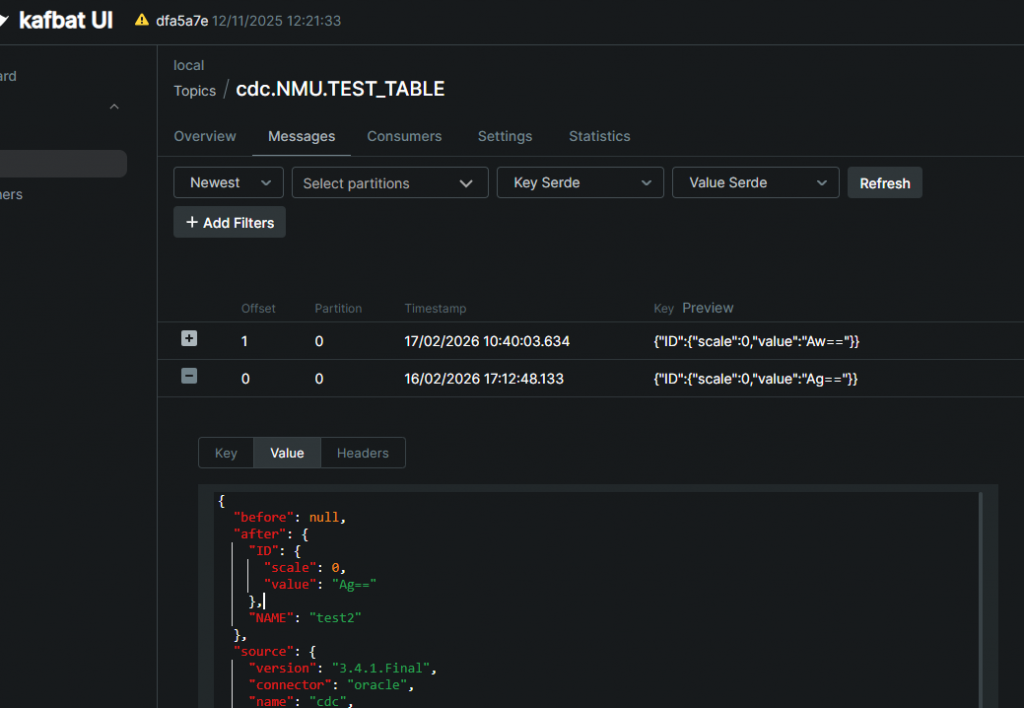
2026-02-17T09:40:15,360 INFO || WorkerSourceTask{id=oracle-cdc-noncdb-0} Committing offsets for 1 acknowledged messages [org.apache.kafka.connect.runtime.WorkerSourceTask]Vous pouvez vérifier aussi côté Kafka, l’idéal est une interface pour visualiser les topics et données comme kafbat ui :
Si vous souhaitez mettre en place des solutions de Data Streaming ou même sur d’autres sujets Data, n’hésitez pas à nous contacter.