

Distribuer du contenu read-only à un pod Kubernetes reste un sujet où chaque équipe a sa recette. Par exemple un site statique, des poids ML, ou un bundle de configs trop gros pour un ConfigMap. On voit alors un initContainer qui télécharge, ou une image runtime gonflée d’un COPY, ou un PVC partagé, ou encore un sidecar git-sync. Aucune n’est mauvaise, mais toutes traînent leurs limites. Or, depuis Kubernetes 1.31, le projet a ajouté une voie de plus : ImageVolume sur Kubernetes. Cette feature permet de monter directement une image OCI comme volume read-only via volumes.image (KEP-4639, alpha en 1.31, beta en 1.33, beta on-by-default en 1.35, GA cible 1.36). Nous l’avons donc testée pendant un après-midi sur notre lab K3S 1.33.5+k3s1. Voici ce qui marche, ce qui surprend, et ce que nous gardons en tête pour la prod.
Pourquoi ImageVolume Kubernetes ?
Notre point de départ : un site statique servi par nginx dans un cluster K3S. Le runtime nginx ne change jamais. En revanche, le contenu HTML, lui, change tout le temps. Avec une approche classique on se retrouve à rebuilder une image qui contient nginx et le HTML à chaque mise à jour de contenu. Cela mélange deux choses qui n’ont aucune raison d’être couplées. L’alternative habituelle, c’est un initContainer qui pull le contenu depuis un bucket S3, ou un PVC, ou un sidecar git-sync. Or, à chaque fois on rajoute une dépendance externe (un bucket, un volume RWX, un repo Git accessible) et un point de panne.
ImageVolume change la donne sur ce cas précis. D’abord, le contenu HTML vit dans une image OCI minimale (FROM scratch + COPY). Ensuite, le contenu est versionné dans le même registry que les images runtime, signé, scanné, taggué. Enfin, le kubelet sait le pull et le présenter au container comme un répertoire normal. Aucun script de bootstrap, aucun rebuild applicatif. L’idée n’est pas neuve (CRI-O proposait déjà des choses similaires) mais l’avoir en standard Kubernetes change la portée. Ainsi, avant de plonger, nous avons relu la doc Kubernetes officielle et la KEP-4639 pour ne pas dire de bêtises sur les promesses du feature gate.
Activer ImageVolume Kubernetes sur K3S 1.33
Notre lab tourne sur un seul nœud Kubernetes; il s’agit de K3S. Le runtime est containerd 2.1.4-k3s1, embarqué par K3S. D’abord, avant de toucher quoi que ce soit, nous voulions vérifier deux choses : la version du cluster, et savoir si le feature gate ImageVolume est connu de l’apiserver. Pour ça on utilise les métriques Prometheus exposées par kubectl --raw /metrics. Cette commande affiche une ligne kubernetes_feature_enabled par feature gate avec son stage.
$ kubectl get nodes
$ kubectl get --raw /metrics | grep ImageVolume
Attention au piège : le 1 en fin de ligne kubernetes_feature_enabled{name="ImageVolume",stage="BETA"} 1 signifie ici que la métrique est enregistrée, pas que la feature est activée. Pour savoir si elle est active, il faut regarder l’arg --feature-gates passé à apiserver et kubelet. Or, sur K3S, ces flags se passent via /etc/rancher/k3s/config.yaml. K3S consomme ce fichier au démarrage du service.
On édite donc config.yaml et on ajoute deux entrées kube-apiserver-arg et kubelet-arg. Le feature gate doit être actif des deux côtés. D’abord, l’apiserver doit accepter le champ volumes.image à l’admission. Ensuite, le kubelet doit savoir construire le mount au lancement du pod.
# /etc/rancher/k3s/config.yaml
disable:
- traefik
kube-apiserver-arg:
- "feature-gates=ImageVolume=true"
kubelet-arg:
- "feature-gates=ImageVolume=true"
Ensuite, on redémarre K3S et on revérifie la métrique. Pas de drame côté pods existants. En effet, containerd ne s’arrête pas pendant le restart de K3S. Donc les conteneurs en cours continuent à tourner. Le control plane est indisponible le temps du restart, environ sept secondes au chrono manuel sur le lab. À prendre comme un ordre de grandeur, pas comme une mesure stable.
$ sudo systemctl restart k3s
$ kubectl get --raw /metrics | grep ImageVolumeSanity test : ImageVolume Kubernetes avec nginx
Notre premier test ne sert qu’à une chose : prouver que le feature gate fonctionne. Plus précisément, on veut vérifier que le kubelet sait construire un mount à partir d’une image OCI quelconque. D’abord, on crée un namespace. Ensuite, on déploie un pod busybox qui monte l’image officielle nginx:1.27-alpine sur /mnt/oci. Le pod inspecte ce qu’il y trouve et retourne le résultat dans ses logs.
$ kubectl create namespace imagevolume-pocYAML du pod sanity-test
Voici le YAML complet du pod. Le bloc qui change par rapport à un pod classique, c’est volumes. Au lieu d’un configMap, secret ou persistentVolumeClaim, on utilise image avec une reference (la même syntaxe que spec.containers[].image) et un pullPolicy. On laisse IfNotPresent ici. Ainsi le kubelet réutilisera l’image si elle est déjà dans le cache containerd.
# sanity-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: sanity-test
namespace: imagevolume-poc
spec:
restartPolicy: Never
containers:
- name: shell
image: busybox:1.36
command:
- sh
- -c
- |
echo '== contents of mounted image =='
ls /mnt/oci
echo
echo '== nginx.conf head =='
head -8 /mnt/oci/etc/nginx/nginx.conf
echo
echo '== write test =='
touch /mnt/oci/should-fail 2>&1 || echo 'RO: cannot write (expected)'
volumeMounts:
- name: oci-vol
mountPath: /mnt/oci
readOnly: true
volumes:
- name: oci-vol
image:
reference: nginx:1.27-alpine
pullPolicy: IfNotPresent
Sortie attendue du pod
On applique le manifest, puis on récupère les logs. Le pod a un restartPolicy: Never. Ainsi, une fois l’inspection faite, il termine en Completed et ne redémarre pas.
$ kubectl apply -f sanity-pod.yaml
pod/sanity-test created
$ kubectl -n imagevolume-poc logs sanity-test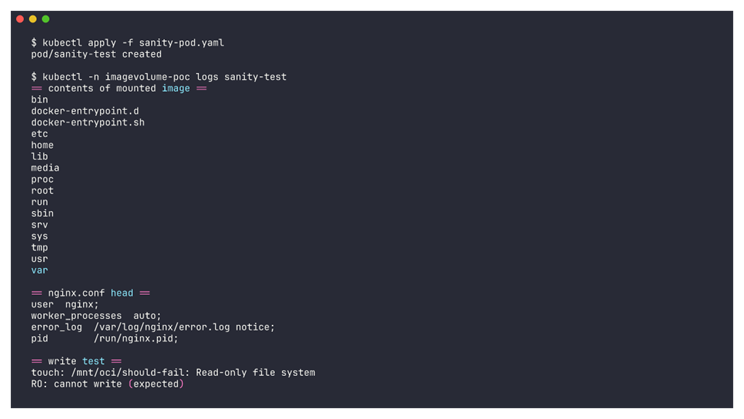
Trois choses sont à retenir dans cette sortie. D’abord, sous /mnt/oci nous avons bien le rootfs nginx complet (etc/, usr/, docker-entrypoint.sh). Le kubelet a déclenché le pull de nginx:1.27-alpine, containerd a extrait ses layers via son snapshotter, et le rootfs assemblé est exposé en mount. Ensuite, nginx.conf est lisible tel quel. Donc on peut récupérer un fichier de configuration depuis une image OCI sans avoir à instancier un container nginx. Enfin, touch échoue avec Read-only file system. Ce n’est pas une question de readOnly: true que nous avons ajouté côté volumeMounts. En effet, on aurait pu enlever ce flag, le résultat serait le même : le kubelet rend le mount read-only par défaut.
ImageVolume Kubernetes pour un site statique
Le sanity test fonctionne, on passe au scénario qui motivait ce POC. L’objectif est de découpler le runtime nginx (qui ne change jamais) du contenu HTML (qui change tout le temps). La recette tient en trois étapes. D’abord, on crée une image OCI qui ne contient que le contenu HTML. Ensuite, on la push sur un registry. Enfin, on la monte dans un Deployment nginx classique.
Build de l’image de contenu
On commence par un index.html minimal et un Dockerfile de deux lignes. FROM scratch garantit qu’on n’embarque aucun rootfs. Ainsi, le layer final ne contient que le fichier copié. C’est le pattern recommandé pour distribuer du contenu via image.
# Dockerfile
FROM scratch
COPY index.html /index.htmlEnsuite, on build et push sur ttl.sh qui sert de registry éphémère pour le POC. Sur ce registry, les images expirent au bout d’une heure. Cela nous convient pour ne pas polluer notre registry avec des artefacts de tests.
$ docker build -t ttl.sh/imagevol-static-e470546e:1h .
$ docker push ttl.sh/imagevol-static-e470546e:1h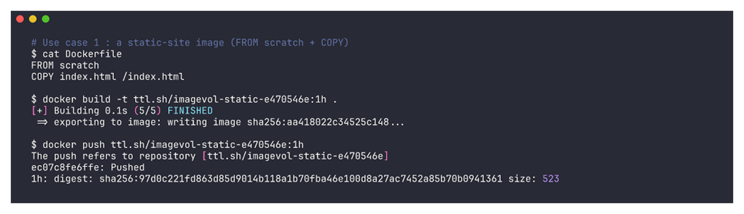
Déployer et tester
Côté Kubernetes, le Deployment qui sert le site est un nginx stock. Ainsi, on n’a aucune modification d’image. Le seul ajout est le volume image monté sur /usr/share/nginx/html, le répertoire que nginx sert par défaut.
# usecase1-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: static-nginx
namespace: imagevolume-poc
spec:
replicas: 1
selector:
matchLabels: { app: static-nginx }
template:
metadata:
labels: { app: static-nginx }
spec:
containers:
- name: nginx
image: nginx:1.27-alpine # runtime stock, jamais rebuild
ports: [{ containerPort: 80 }]
volumeMounts:
- name: site
mountPath: /usr/share/nginx/html
readOnly: true
volumes:
- name: site
image:
reference: ttl.sh/imagevol-static-e470546e:1h
pullPolicy: AlwaysEnsuite, on apply, on expose en Service ClusterIP. Puis on teste depuis l’intérieur du cluster avec un pod curl jetable. Donc kubectl run avec --rm sert exactement à ça : un test ad-hoc qui se nettoie tout seul à la sortie.
$ kubectl apply -f usecase1-deploy.yaml
$ kubectl -n imagevolume-poc expose deploy static-nginx --port=80
$ kubectl -n imagevolume-poc get deploy,svc,pod -l app=static-nginx
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/static-nginx 1/1 1 1 14s
NAME TYPE CLUSTER-IP PORT(S)
service/static-nginx ClusterIP 10.43.118.207 80/TCP
NAME READY STATUS RESTARTS AGE
pod/static-nginx-7c9bfd5f8b-q7r2m 1/1 Running 0 14sLe pod est Running. Le Service ClusterIP est attribué dans la foulée. Ensuite, on curl le contenu pour confirmer que ce que sert nginx vient bien de notre image OCI de contenu, et non d’un quelconque index.html par défaut.
$ kubectl -n imagevolume-poc run curl-test \
--image=curlimages/curl:8.10.1 \
--restart=Never --rm -i --quiet -- \
curl -s http://static-nginx.imagevolume-poc.svc.cluster.local/index.html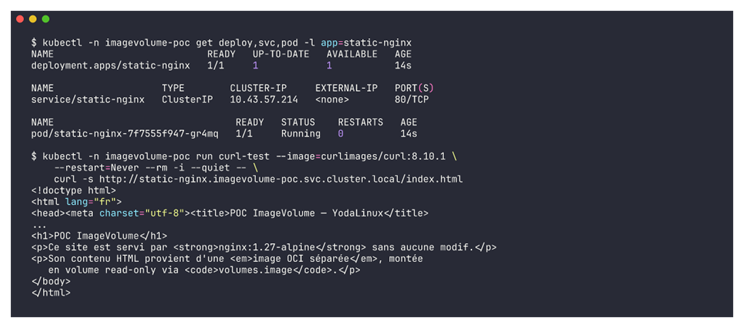
Donc pour publier une nouvelle version du site, on rebuild l’image de contenu. Ensuite, on push avec un nouveau tag (ou on retag fixe + pullPolicy: Always). Enfin, on fait un kubectl set image sur le volume. L’image runtime nginx ne bouge pas. Aucun rolling update touchant à nginx, aucun rebuild applicatif. Ainsi, c’est exactement le découplage qu’on cherchait. Cependant, pour des workloads stateful sur Kubernetes nous avons d’autres mécaniques en tête. Nous avions documenté l’une d’elles dans PostgreSQL sur Kubernetes avec CloudNativePG.
Use case 2 : config bundle, image vs OCI artefact
Notre deuxième scénario, c’est de distribuer un bundle de configurations qui dépasse la limite d’un ConfigMap. Cette limite est de 1 MiB par défaut, et correspond à etcd request size. Disons un app.yaml, un rules.json de quelques centaines de Ko, et un MANIFEST.txt. On veut les versionner et les distribuer comme un binaire.
Tentative avec un artefact OCI pur
Notre premier réflexe a été de créer un artefact OCI pur via oras, pour voir comment ImageVolume Kubernetes traite ce format. L’idée était propre sur le papier : un mediaType custom, pas de rootfs tar, juste les fichiers tels quels dans le manifest. Ainsi, c’est typiquement ce que fait Helm pour pousser des charts en OCI, ou cosign pour pousser des signatures.
$ oras push ttl.sh/imagevol-config-0a3b11f4:1h \
--artifact-type application/vnd.demo.config.bundle.v1+json \
app.yaml:application/yaml \
rules.json:application/json \
MANIFEST.txt:text/plainEnsuite, on déploie un pod consumer qui monte cet artefact via volumes.image. Le YAML reprend la structure du sanity-pod, avec trois changements : nom du pod, mountPath sur /etc/config, et la référence pointe sur l’artefact oras.
# artifact-consumer.yaml
apiVersion: v1
kind: Pod
metadata:
name: artifact-consumer
namespace: imagevolume-poc
spec:
restartPolicy: Never
containers:
- name: shell
image: busybox:1.36
command:
- sh
- -c
- |
echo '== layers in mounted artifact =='
ls -la /etc/config
echo
echo '== app.yaml =='
cat /etc/config/app.yaml
volumeMounts:
- name: cfg
mountPath: /etc/config
readOnly: true
volumes:
- name: cfg
image:
reference: ttl.sh/imagevol-config-0a3b11f4:1h
pullPolicy: AlwaysOn apply, on lit les logs.
$ kubectl apply -f artifact-consumer.yaml
$ kubectl -n imagevolume-poc logs artifact-consumer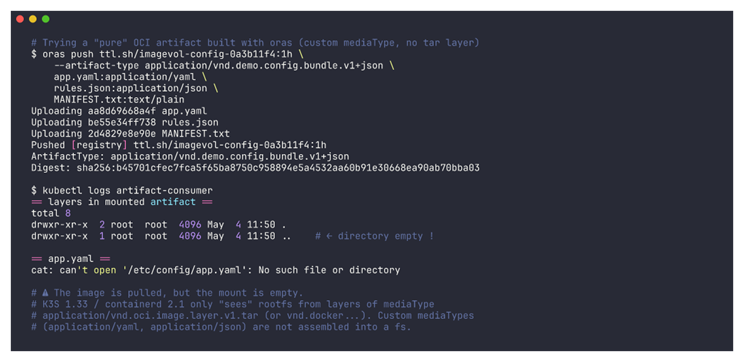
Le pod démarre sans erreur. Cependant, la commande ls dans /etc/config retourne un répertoire vide. Constat empirique sur K3S 1.33 et containerd 2.1 : l’image est pull et présente dans le cache containerd, mais le mount ne contient rien. En effet, ImageVolume reconstruit un filesystem à partir de layers de mediaType application/vnd.oci.image.layer.v1.tar ou application/vnd.docker.image.rootfs.diff.tar.gzip. Or des layers de mediaType arbitraire (application/yaml, application/json) sont stockés dans le cache mais ne sont pas assemblés en rootfs. Ainsi, la doc upstream parle bien d’OCI object, mais en pratique sur cette version, seules les images au sens classique fonctionnent pour le mount. C’est cohérent avec le comportement de containerd qui n’a pas de logique d’assemblage générique pour des mediaTypes inconnus.
Workaround : image FROM scratch
Donc le pattern qui marche pour ImageVolume Kubernetes, c’est de pousser ces mêmes fichiers comme une image OCI traditionnelle. Avec FROM scratch + COPY, on obtient un layer tar standard. Et celui-ci est montable directement par ImageVolume.
# Dockerfile
FROM scratch
COPY app.yaml rules.json MANIFEST.txt /
$ docker build -t ttl.sh/imagevol-config-img-26eac4ca:1h .
$ docker push ttl.sh/imagevol-config-img-26eac4ca:1hEnsuite, avec ce nouveau tag, on relance un pod consumer. La structure reprend celle d’artifact-consumer.yaml, avec un autre nom de pod et la référence qui pointe sur l’image FROM scratch qu’on vient de pousser.
# configbundle-consumer.yaml
apiVersion: v1
kind: Pod
metadata:
name: configbundle-consumer
namespace: imagevolume-poc
spec:
restartPolicy: Never
containers:
- name: shell
image: busybox:1.36
command:
- sh
- -c
- |
echo '== layers in mounted artifact =='
ls -la /etc/config
echo
echo '== app.yaml =='
cat /etc/config/app.yaml
volumeMounts:
- name: cfg
mountPath: /etc/config
readOnly: true
volumes:
- name: cfg
image:
reference: ttl.sh/imagevol-config-img-26eac4ca:1h
pullPolicy: Always$ kubectl apply -f configbundle-consumer.yaml
$ kubectl -n imagevolume-poc logs configbundle-consumer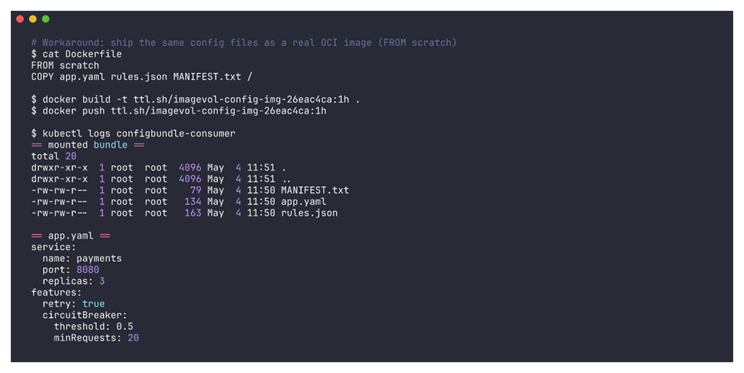
Cette fois, on récupère bien les fichiers : app.yaml, rules.json et MANIFEST.txt sont visibles dans /etc/config avec leur contenu intact. À retenir : si votre outillage vous pousse vers oras pour distribuer des configs, deux options se présentent. Soit un sidecar qui les pull et les écrit sur un emptyDir. Soit, plus simple, réemballer ces mêmes fichiers dans une image OCI classique. Ainsi, la deuxième solution évite tout code de glue et reste fidèle au pattern ImageVolume.
ImageVolume Kubernetes et subPath
Avec un volume ConfigMap ou Secret, nous avons l’habitude d’utiliser subPath. Cela permet de projeter un seul fichier dans un chemin précis. Par exemple monter app.yaml sur /etc/app/app.yaml sans exposer le répertoire entier. Or, avec ImageVolume, nous avons voulu tester la même mécanique. Cependant, ça ne marche pas comme attendu.
On part de l’image FROM scratch qui contient déjà app.yaml, et on déploie un pod subpath-consumer qui demande à monter uniquement ce fichier sur /etc/app/app.yaml via subPath.
# subpath-consumer.yaml
apiVersion: v1
kind: Pod
metadata:
name: subpath-consumer
namespace: imagevolume-poc
spec:
restartPolicy: Never
containers:
- name: shell
image: busybox:1.36
command:
- sh
- -c
- |
echo '== cat /etc/app/app.yaml =='
cat /etc/app/app.yaml 2>&1 || true
echo
echo '== ls -la /etc/app =='
ls -la /etc/app
volumeMounts:
- name: cfg
mountPath: /etc/app/app.yaml
subPath: app.yaml # attendu : mount fichier ; observe : mount repertoire (cf. capture)
readOnly: true
volumes:
- name: cfg
image:
reference: ttl.sh/imagevol-config-img-26eac4ca:1h
pullPolicy: IfNotPresent$ kubectl apply -f subpath-consumer.yaml
$ kubectl -n imagevolume-poc logs subpath-consumer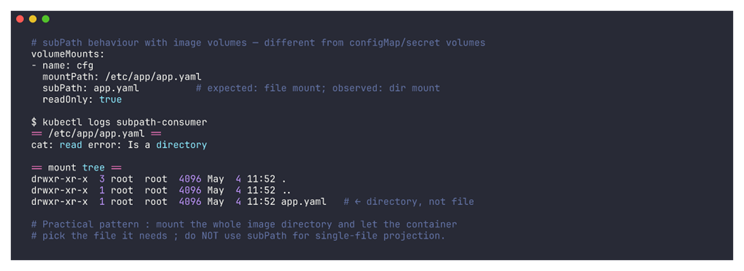
Nous n’avons pas trouvé de mention explicite de ce comportement dans la doc Kubernetes au moment du test. Or, le comportement diffère clairement de celui de configMap ou secret avec subPath. On suppose que c’est lié à la façon dont containerd expose le rootfs de l’image. En effet, c’est un mount unique de répertoire, que Kubernetes traite différemment de l’extraction par fichier que fait l’objet ConfigMap. Donc le pattern à appliquer en attendant : monter le répertoire entier de l’image et laisser l’application piocher le fichier dont elle a besoin. Cependant, si la projection mono-fichier est non négociable, ConfigMap reste plus adapté.
Quand utiliser ImageVolume Kubernetes
Bons cas d’usage
- Site statique servi par un runtime générique (nginx, caddy, httpd), pour découpler le runtime du contenu.
- Modèles ML / weights distribués via le registry (versionnage, signature cosign, scan trivy, le tout déjà géré par la chaîne CI image).
- Datasets read-only de référence (datasets de test, géo-données figées, fichiers de fixtures).
- Bundles de configuration qui dépassent la limite ConfigMap (1 MiB) et qu’on veut versionner comme un binaire.
- Plugins ou extensions compilés livrés à un runtime générique. Pour les pipelines de données temps réel à côté, nous avions aussi écrit sur Streamer les changements Oracle vers Kafka en temps réel.
Limites observées sur K3S 1.33
- Les artefacts OCI purs (mediaType custom, pas de tar layer) ne donnent pas de rootfs montable. Workaround : image FROM scratch + COPY.
- Le
subPathproduit un répertoire, pas un fichier ; ne pas l’utiliser pour la projection mono-fichier. - Le mount est strictement read-only par construction. Si on veut du writable éphémère par-dessus, on combine avec un
emptyDir. - Le
pullPolicyest respecté comme pour les images runtime ;Always= call registry à chaque démarrage de pod, à utiliser avec discernement sur les workloads à fort taux de redémarrage. - L’image n’est pas reflétée dans
status.containerStatusesdu pod ; pour auditer ce qu’un pod monte réellement, lirespec.volumes.
Conclusion
Sur K3S 1.33, ImageVolume sur Kubernetes tient ses promesses pour le cas le plus courant. Ainsi, on peut distribuer du contenu versionné via le même registry que les images runtime, sans rebuild applicatif. Le sanity test, le site statique et le bundle de configs se mettent en place en quelques minutes. Cependant, les rough edges constatés (artefacts purs non montables, subPath qui donne un répertoire) ne sont pas bloquants tant qu’on reste sur le pattern image OCI classique. Enfin, l’arrivée en GA cible Kubernetes 1.36 (toujours selon la KEP) enlèvera la barrière feature gate. En revanche, le comportement, lui, ne change pas.
Nos deux prochaines expérimentations sur ce lab. D’abord, comparer la latence de boot d’un pod avec ImageVolume (pullPolicy: Always, registry distant) à celle d’un pod montant un PVC RWX. Ensuite, tester la combinaison ImageVolume + cosign verification au niveau du kubelet, pour ne monter que des images signées. Si vous avez déjà testé l’un ou l’autre, nous sommes preneurs de retours.
Aller plus loin avec ImageVolume Kubernetes en production
Ce POC vous a donné envie de pousser ImageVolume Kubernetes au-delà du lab ? Axians est certifié Kubernetes et accompagne au quotidien des organisations qui exploitent la plateforme en production. Pas en démo, pas en POC : sur des clusters qui portent du trafic réel et leur lot d’incidents nocturnes. Notre offre Cloud Native s’articule autour de trois pôles : la formation, l’accompagnement, et le maintien en condition opérationnelle.
Nos formations Kubernetes
- Introduction à Kubernetes et aux opérateurs : notre best-seller. Pour les équipes qui découvrent la plateforme, du pod jusqu’aux operators custom, et qui veulent une base solide en quelques jours.
- Kubernetes pour la production : centrée sur Helm et ArgoCD, pour mettre en place une chaîne GitOps robuste et auditable.
- CNPG Operator : pour exploiter PostgreSQL en cloud-native sans concession. À ce titre, Axians est référencé par EnterpriseDB comme support officiel de CNPG Operator.
Accompagnement et conseil
- Transition de Docker vers Kubernetes : audit de l’existant, gap analysis, plan de migration applicatif et opérationnel, sans rupture pour vos équipes.
- Gouvernance Kubernetes : organisation, modèles d’équipe, sécurité, FinOps, pour adopter la plateforme sereinement et garder le contrôle dans la durée.
- Adaptation des pratiques Dev et Ops : pipelines CI/CD, observabilité, SRE, runbooks d’incident. Nous travaillons avec vos équipes existantes, pas à leur place.
MCO Kubernetes : trois niveaux d’engagement
- Silver : un coup de pouce ponctuel quand un sujet vous coince. Vous gardez la main sur votre cluster, nous intervenons à la demande.
- Gold : supervision en heures ouvrées (9h – 18h), alerting temps réel, notre équipe est notifiée dès qu’un incident intervient.
- Platinium : 24 / 7. Astreinte, SLA stricts, gestion d’incident continue. Pour les workloads critiques qui ne peuvent pas attendre le lendemain matin.
Si l’un de ces sujets résonne avec votre contexte, écrivez-nous. Une heure d’échange suffit en général à clarifier ce dont vous avez vraiment besoin, et à voir si nous sommes le bon partenaire pour vous. Vous pouvez nous joindre via le formulaire de contact d’axiansdb.com, ou directement à votre interlocuteur Axians habituel.